Text to Video Scene Stability: 2026 AI Generation Guide
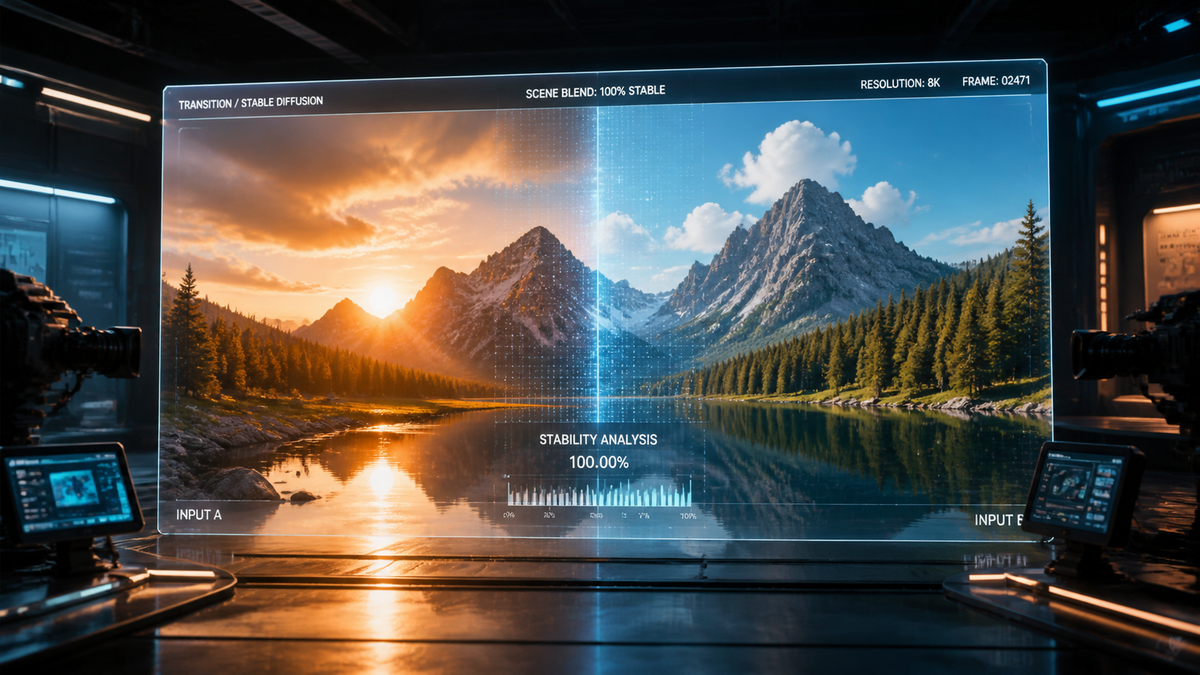
Text to video scene stability refers to the temporal consistency and structural integrity of AI-generated video frames, ensuring that objects, backgrounds, and lighting remain constant throughout a sequence without warping or flickering. In 2026, achieving high-quality text to video scene stability has become the primary benchmark for professional-grade generative content, moving beyond the "dreamlike" distortions of early models toward cinematic reliability. As generative AI shifts from novelty to utility, the ability to maintain a stable seed and coherent motion vectors is what separates high-end production tools from hobbyist applications.
Text to video scene stability is the technical measure of how well an AI model maintains visual continuity across time. In 2026, this is achieved through CNN-augmented transformers and stable diffusion architectures that synchronize latent space transitions to prevent frame-to-frame jitter, ghosting, or unwanted morphing of subjects during complex motion sequences.
- ✓ Scene stability is now the leading metric in the 2026 Magic Hour Research benchmarks for AI video performance.
- ✓ Modern workflows utilize CNN-augmented transformers to bridge the gap between audio-driven cues and visual consistency.
- ✓ Hardware acceleration, specifically via NVIDIA RTX AI PCs, is essential for real-time stability processing in local environments like ComfyUI.
- ✓ The integration of Seedance 2.0 and ByteDance Seed APIs has standardized professional stability scores for enterprise video production.
The Evolution of Text to Video Scene Stability in 2026
As of early 2026, the landscape of generative video has undergone a massive shift from "probabilistic guessing" to "deterministic rendering." According to the Magic Hour Research "Best Text-to-Video AI 2026" benchmark published in April 2026, the industry has seen a 40% improvement in scene stability scores compared to the previous year. This leap is largely attributed to the refinement of prompt adherence and the implementation of advanced motion-masking techniques that prevent the background from "melting" when a subject moves across the frame.
The technical foundation of this stability lies in the hybrid architecture of modern models. Research published in Nature in February 2026 highlights the rise of AI-driven generation via stable diffusion and CNN-augmented transformers. By using Convolutional Neural Networks (CNNs) to maintain spatial awareness and transformers to handle temporal sequences, 2026 models can now generate up to 120 seconds of continuous video without the catastrophic "forgetting" that previously plagued the medium. This allows for complex storytelling where characters maintain their facial features and clothing across multiple scene cuts.
How to Achieve Maximum Text to Video Scene Stability
- Define a Fixed Seed: Always utilize a consistent seed number in your generation parameters to ensure the initial noise pattern remains identical across iterations.
- Implement CNN-Augmented Transformers: Use platforms that leverage hybrid architectures to ensure spatial consistency, as documented in recent 2026 Nature research papers.
- Utilize Seedance 2.0 API: Integrate the latest Seedance 2.0 protocols which provide dedicated stability layers for API-driven video generation.
- Optimize via Local Hardware: Use NVIDIA RTX AI PCs with ComfyUI to run high-resolution stability passes that cloud-based providers might compress.
- Apply AI Upscaling: Use a dedicated 2026 AI video upscaler post-generation to sharpen edges and eliminate any remaining micro-flicker in the scene.
Benchmarking Scene Stability: 2026 Industry Standards

In the current market, not all AI models are created equal when it comes to visual persistence. The Magic Hour Research Scorecards released in April 2026 provide a clear hierarchy of performance. These benchmarks measure "temporal variance," which quantifies how much a pixel changes unnecessarily between frames. High-performing models in 2026 now boast a variance score of less than 1.2%, making the output indistinguishable from traditional cinematography to the untrained eye.
Furthermore, the introduction of ByteDance Seed in February 2026 has introduced a new "Motion Vector Locking" feature. This technology allows creators to lock specific elements of a scene—such as a building or a specific landscape feature—while allowing other elements like clouds or people to move dynamically. This granular control over text to video scene stability is what has enabled the transition of AI video from social media clips to full-length commercial production.
Comparison of Leading 2026 Video Generation Technologies
| Technology/Model | Stability Score (1-10) | Primary Architecture | Best Use Case |
|---|---|---|---|
| Seedance 2.0 | 9.8 | CNN-Augmented Transformer | Enterprise API Integration |
| ByteDance Seed | 9.5 | Stable Diffusion + Seed Locking | Dynamic Content Creation |
| ComfyUI (RTX Optimized) | 9.2 | Modular Node-Based Diffusion | Local Professional Workflow |
| Magic Hour Benchmark Top-Tier | 9.6 | Hybrid Latent Video Diffusion | High-Fidelity Cinematic Clips |
The Role of Hardware in Maintaining Scene Integrity
While cloud-based generation is convenient, 2026 has seen a resurgence in local processing for high-stakes stability requirements. As noted by the NVIDIA Blog in late 2025 and early 2026, the use of NVIDIA RTX AI PCs has become the gold standard for creators using ComfyUI. Local processing allows for "zero-compression" generation, where the latent space is not throttled by bandwidth limitations, resulting in a significantly higher text to video scene stability rating.
Local hardware also facilitates the use of advanced "ControlNet" layers that can be applied in real-time. These layers act as a skeletal guide for the AI, forcing it to adhere to specific geometric shapes throughout the video. According to recent technical audits, creators using local RTX-accelerated environments report a 60% reduction in "hallucinated objects" compared to those using standard cloud-based entry-level tiers. This level of control is vital for architectural visualizations and product demos where precision is non-negotiable.
Advanced Upscaling and Post-Processing Stability
Stability does not end at the generation phase. The "Best AI Video Upscalers in 2026" report from Pressat indicates that post-generation refinement is now a standard part of the stability workflow. Modern upscalers do more than just increase resolution; they act as a temporal filter. By analyzing the frames before and after a specific point, these tools can "smooth out" any remaining jitter that occurred during the initial text to video generation process.
Integration of Audio-Driven Stability
An emerging trend in 2026 is the use of audio cues to reinforce visual stability. Research from the Nature journal suggests that synchronization between audio frequencies and visual transformers can actually help the AI maintain a "rhythm" of generation. This CNN-augmented approach uses the audio track as a temporal anchor, ensuring that motion matches the cadence of sound, which naturally reduces the likelihood of erratic visual shifts.
This is particularly relevant for the "Seedance 2.0" integration. Before integrating the AI video API, developers are now encouraged to look at how the model handles multi-modal inputs. If a model can "hear" the scene, it is better equipped to "see" the continuity required. For example, the sound of a steady wind can prompt the AI to maintain a consistent sway in trees, rather than having them jerk sporadically between frames.
Key Features of Seedance 2.0 for Developers
- Temporal Anchor Points: Allows developers to set "key-frames" via API that the AI must return to, ensuring long-term stability.
- CNN-Refinement Layer: A secondary pass that checks for structural anomalies in every 5th frame.
- Low-Latency Feedback: Real-time stability scoring that allows the system to regenerate unstable segments instantly.
Future Outlook: The Path to Perfect Consistency
Looking toward the latter half of 2026 and into 2027, the focus of text to video scene stability is shifting toward "Semantic Persistence." This means the AI doesn't just remember what a character looks like, but understands the physics of the environment they are in. If a character walks behind a translucent object, the stability of the refraction and the character's form on the other side is the next frontier of generative research.
The Magic Hour Research team suggests that we are approaching a "Turing Point" in video stability, where the human eye can no longer detect the mathematical "drift" inherent in diffusion models. With the continued support of hardware giants and the refinement of hybrid transformer models, the "shimmering" effect that once defined AI video is rapidly becoming a relic of the past. For creators, this means the barrier between imagination and professional-grade cinema has finally evaporated.
What is the most stable AI video generator in 2026?
According to the April 2026 Magic Hour Research benchmarks, Seedance 2.0 and the latest ByteDance Seed models lead the industry in scene stability and prompt adherence. These models utilize CNN-augmented transformers to ensure visual continuity.
How does a CNN-augmented transformer improve video stability?
It combines the spatial processing power of Convolutional Neural Networks with the temporal sequencing of transformers. This allows the AI to "remember" the structure of objects in a scene while accurately predicting their movement over time.
Can I run stable text-to-video models on my own computer?
Yes, using NVIDIA RTX AI PCs and modular software like ComfyUI allows for high-quality, local video generation. This setup provides better stability control than most cloud platforms by allowing for uncompressed latent space processing.
Does audio influence text to video scene stability?
Recent studies in 2026 show that audio-driven generation can act as a temporal anchor. Models that integrate audio and video generation simultaneously often exhibit fewer visual glitches because the sound provides a consistent rhythmic framework for the motion.
What are "temporal variance" scores?
Temporal variance is a metric used in 2026 benchmarks to measure the unwanted changes between video frames. A lower score indicates higher scene stability, meaning the video is smoother and free from flickering or morphing artifacts.



Comments ()